
Technical Articles
Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents

The problem we kept running into
We kept hitting the same wall: our system was generating better models, but could no longer tell which one was actually better.
MLEvolve is one of the strongest open-source ML search agents available today, which is why we use it as our testbed. Like many recent agent-based systems, it explores a search tree of candidate solutions: generate, evaluate, iterate.
Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 1 The point is not that the problem is unique to MLEvolve.
Any agent that relies on proxy-based evaluation to guide a search tree eventually faces the same issue: if the evaluation signal becomes noisy or miscalibrated, the entire search starts optimizing the wrong thing. Evaluating a candidate means training a model, and training takes time. You cannot fully train every candidate, so you rely on a cheap proxy evaluation: limited data, bounded steps, strict timeouts. In practice, this creates two problems.
First, defining a proxy that is actually reliable is much harder than it sounds. In many setups, candidates are given loose constraints, maybe just a timeout, and allowed to do whatever they want. This opens the door to subtle failure modes: hidden inner loops, ignored arguments, or even scripts that compute and print their own metrics. At that point, the score is no longer trustworthy, and the search starts optimizing exploits instead of real performance.
Second, even when the proxy is well-defined, it quickly becomes a bottleneck. Early in the search, it works well. But as candidates improve, scores collapse into a narrow band, differences become indistinguishable from noise, and the search stalls. There is also a more practical issue.
Many agent-based systems report strong results, but these often come from running the system dozens or hundreds of times and selecting the best outcome. In other words, performance is achieved through repeated sampling and a degree of luck - one run eventually takes the right direction. This is exactly what we wanted to avoid.
Our goal was not just to improve performance, but to make it reliable: when you launch a run, you should have a high probability of getting a strong result, without relying on repeated attempts or manual selection. We needed a proxy that could not be gamed, and a system that could keep it informative over time. So we designed a strict evaluation protocol: fixed training budget, controlled execution environment, and a scoring function computed externally.
This makes Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 2 the proxy robust and trustworthy, but not necessarily informative enough as the search progresses. Designing a more informative proxy signal Instead of relying on a single final metric, we evaluate candidates at multiple points during training and aggregate the trajectory into a single score.
This proxy signal is designed to capture three complementary aspects of learning: overall performance across the training trajectory (not just the final point) improvement over time (does the model keep getting better?) stability of training (is the signal consistent or noisy?) The goal is to favor solutions that learn consistently and reliably, rather than those that spike early or behave erratically. In practice, this helps surface models that may not look impressive in the first few steps, but show strong and stable improvement - a much better indicator of long term performance. But even with a robust proxy, a second issue remains.
As candidates improve, the proxy loses its ability to distinguish between them. Scores collapse into a narrow band, and differences become indistinguishable from noise. From that point on, ranking is no longer driven by signal, but by randomness. And once that happens, the search is effectively blind.
The first idea: run in two phases A natural solution is simple: start with a cheap proxy, then increase evaluation fidelity when more resolution is needed. Use a low-fidelity proxy for broad exploration, then switch to a higher-fidelity one for refinement. We tried this. In practice, it didn’t work well.
The main issue was deciding when to switch. Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 3 Switch too early and you increase evaluation cost too quickly, reducing the number of iterations and limiting the agent’s ability to discover strong candidates Switch too late and you spend most of your budget on a proxy that is no longer informative, where candidates cannot be reliably ranked
The core challenge is balancing iteration count and evaluation fidelity: the goal is to maximize the number of informative iterations, not just iterations. On top of that, the right timing is highly task-dependent. A tabular problem and a long-horizon sequence model behave very differently. Each new task required pilot runs just to calibrate the proxy before the actual search could even begin. In practice, we were spending as much time tuning the system as actually using it.
The actual solution:
let the system supervise itself The key insight was simple: If the system can observe that the proxy has stopped being informative, it can decide to tighten it on its own. No pilot runs. No hardcoded thresholds. No human in the loop. This is the role of the Overseer Agent.
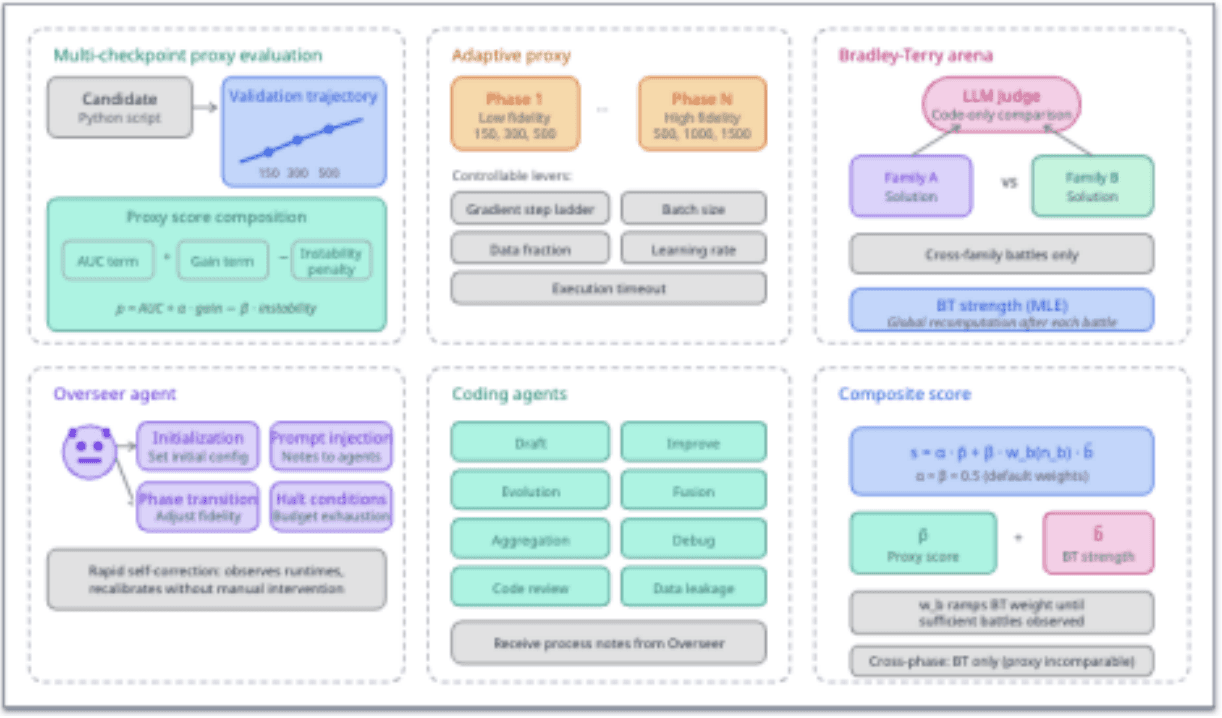
Figure 2: System overview. Candidates are scored by a fixed proxy within each phase. An Overseer Agent watches for stagnation and increases evaluation fidelity at phase transitions. A Bradley-Terry arena provides an independent ranking signal through cross-family LLM-judged battles.
An Overseer Agent watches for stagnation and increases evaluation fidelity at phase transitions. A Bradley-Terry arena provides an independent ranking signal through cross-family LLM-judged battles. A useful way to think about it is as a project manager, not an engineer. It does not write code, does not suggest architectures, and does not tune hyperparameters. It has no opinion on what solution should be built. Its role is purely to manage how the search is run: defining the initial evaluation setup, monitoring progress, detecting stagnation, triggering phase transitions, and injecting process-level guidance when something goes structurally wrong.
This separation is intentional. The ML agents are responsible for generating and improving solutions. The Overseer is responsible for managing the evaluation budget and trajectory. If it were allowed to influence technical decisions, it would introduce premature convergence pressure and bias the search toward early, potentially suboptimal directions.
In practice, the Overseer operates on a coarse time scale. It checks in every N iterations (in our case, every 25 completed candidate evaluations), reviews the evolution of the best scores, and asks a simple question: is the current proxy still providing useful signal? If progress has stalled for long enough, it considers whether a phase transition is warranted, taking into account both the observed stagnation and the remaining budget. The goal is not to react to noise, but to adjust evaluation fidelity only when the current setup has clearly stopped being informative.
Why gradient steps - and why it matters more than you’d think
To make this work, we first needed a reliable way to define and control the training budget. Epochs seem like the natural choice. They are not. MLEvolve operates across very different data regimes: independent rows, sequences, time series, variable-length inputs. An “epoch” does not represent a consistent quantity across these settings.
The same epoch count can correspond Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 5 to vastly different amounts of actual training depending on how the data is structured. This makes epochs unreliable. Small implementation differences can silently multiply training cost by 10× or more. Gradient steps are a much more stable alternative.
They directly control the number of parameter updates, regardless of how the data is organized. Enforcing the same number of steps across candidates ensures controlled comparisons. But this is not perfect either.
A step over long sequences is more expensive than a step over independent rows. Differences in model architecture and input structure still affect compute. Gradient steps ensure fairness in updates, not perfect fairness in compute.
This is a deliberate trade-off. Other units, such as epochs, tokens, or wall-clock time, introduce even more instability. Gradient steps provide a robust and implementation-resistant baseline.
To make this meaningful in practice, we complement gradient steps with a second concept: how much data each candidate actually sees during training.
The Overseer controls two levers: how much data is used how long each candidate trains on it If the goal is to see more data, it increases the dataset size and scales the number of steps accordingly so that training coverage stays roughly consistent.
This increases breadth: candidates see more of the dataset. If the goal is to refine promising solutions, it increases how long candidates train on the same data. This increases depth.
In practice, the Overseer can adjust either or both, depending on what the search needs at that moment.
What the Overseer actually does at each phase transition
The Overseer has four levers: Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 6 Gradient step ladder - the checkpoints at which validation metrics are recorded, e.g. [200, 400, 600] → [400, 800, 1200] Data fraction - what share of the training set each evaluation uses Execution timeout - a hard wall-clock cap, not a soft limit Batch size - occasionally adjusted for memory reasons
The direction is not always upward. If candidates are timing out or producing unstable trajectories, the Overseer can reduce these settings. The timeout is particularly important: it is not advisory. A candidate that ignores the gradient step argument and keeps training past the budget will be killed. This prevents a class of subtle cheating where a script runs indefinitely and accumulates a better score than it would under the intended evaluation protocol.
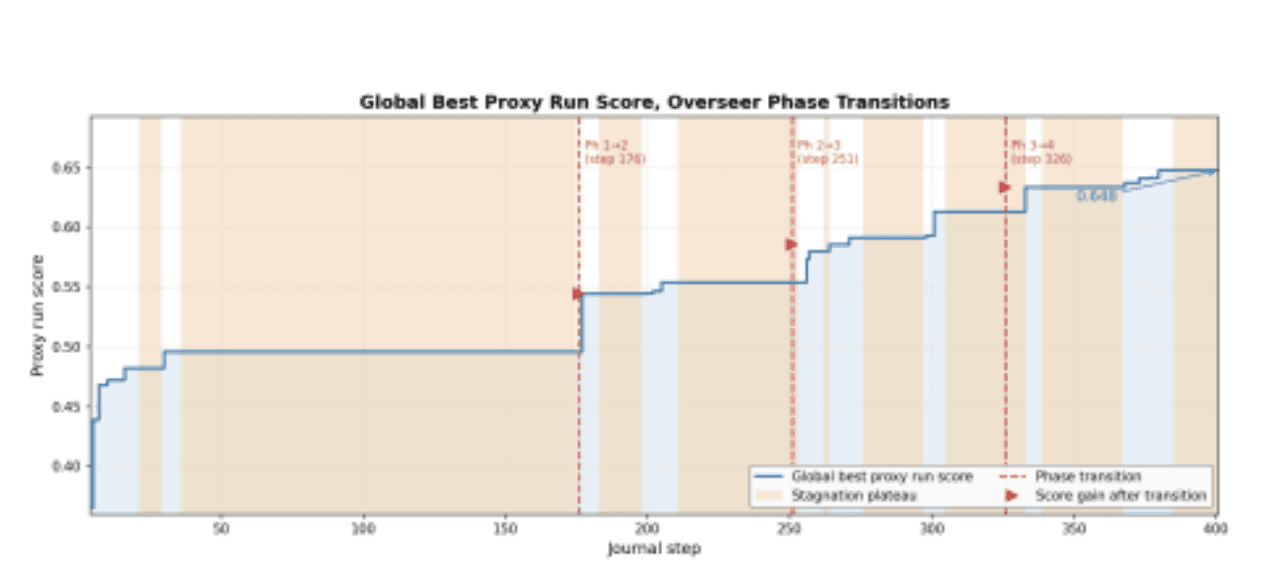
Figure 3: Global best proxy score over 392 evaluated nodes. Dashed red lines mark Overseer-triggered phase transitions (steps 176, 251, 326). Orange regions are the stagnation plateaus. Each transition produces a visible score jump - the higher-fidelity proxy immediately reveals differences the cheaper proxy was smoothing over.
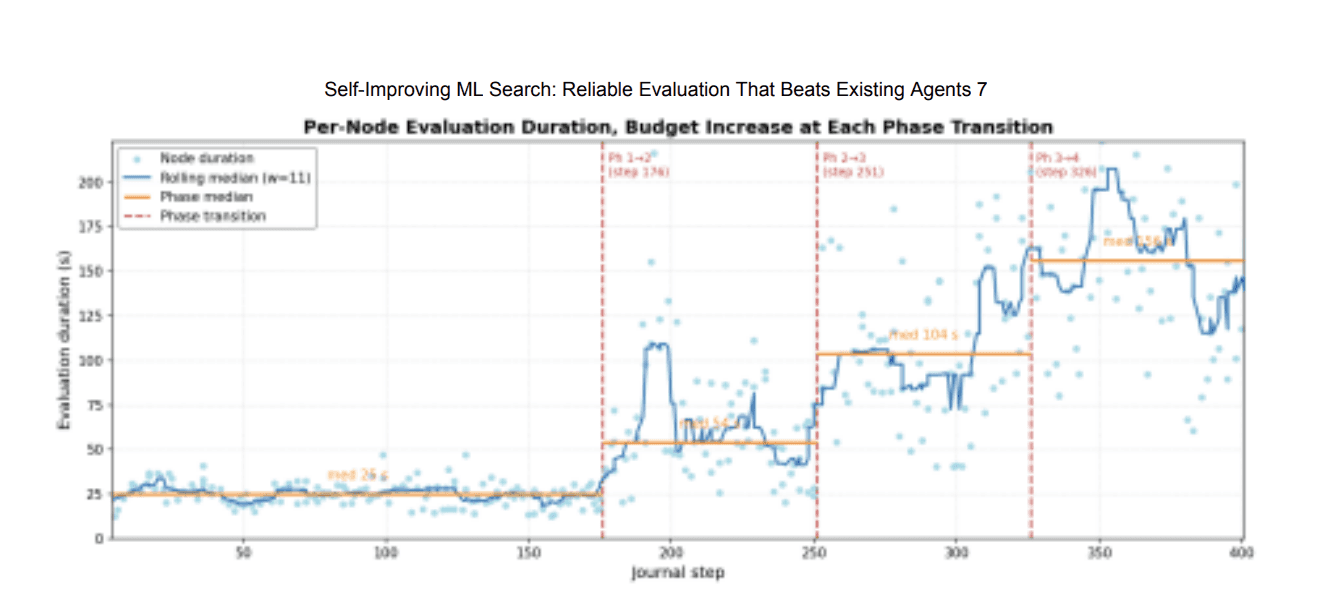
Figure 4: Per-node evaluation time across the run. Phase transitions produce step increases in cost. Phase medians: ~25 s, 54 s, 104 s, 156 s - a 6× increase from
Phase 1 to Phase 4 :
Here is what actually happened on Ventilator, in the Overseer’s own words at each transition: Before launch - initialization.
The Overseer reads the data before any candidate is evaluated: “The task is sequence-based (80 rows per breath), so models will likely process full breaths.
A 5% data fraction yields ~3,395 training sequences. Using a batch size of 64, 600 gradient steps provides roughly 11.3 local epochs. At ~0.1 s per step for RNNs, a node will take about 1–2 minutes, allowing thousands of iterations to establish a robust ranking signal before any heavy exploitation.
”Steps 76–100 - stagnation detected, Phase 1 held. The Overseer sees a 9-step plateau but decides not to act: “The search is still in the early exploration phase (18% of wall-clock budget elapsed). Although there is a 9-step stagnation, scores are reasonably spread (0.43 to 0.49) and multiple families are actively developing. Strict conditions for increasing proxy cost are not met.
We will maintain the current configuration to maximize architecture exploration.” Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 8 This is the kind of judgment a static rule cannot make.
The same stagnation signal at 45% of the budget triggers a transition; at 18% it does not. Steps 176–200 - Phase 1→2 transition. Now it acts: “The search has reached 45% of the wall-clock budget with 6 families clustered between 0.475 and 0.495. A 9-step stagnation indicates the current proxy lacks the resolution to separate these models. We are doubling data fraction to 0.10 and doubling eval-grad-steps to 1200. This increases node time to ~45 s, allowing over 500 more evaluations in the remaining 392 minutes.” Steps 251–275 - Phase 2→3, and 326–350 - Phase 3→4.
The same logic repeats: detect stagnation, estimate remaining budget, adjust fidelity. By the final transition, only 8% of the budget remains and the top families are separated by 0.02 proxy points. The Overseer raises fidelity one last time to give the tie breaking comparisons a sharper signal.
Bradley-Terry: the ranking signal that survives phase transitions
Even with an adaptive proxy, two problems remain.
First, proxy scores favor models that learn quickly. Architectures that converge more slowly may be systematically undervalued.
Second, proxy scores are not comparable across phases. A score obtained under one evaluation setup does not mean the same thing as a score obtained under another.
To address this, we introduce a second, independent signal: pairwise comparisons between solutions. Instead of relying only on scalar scores, we directly compare candidate implementations. A judge receives two solutions and selects the stronger one based on code quality and architectural soundness.
These comparisons are primarily conducted across different solution families, where structural differences are the most informative. There is one important exception: when comparing candidates from different phases within the same family, where proxy scores are no longer comparable, we Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 9 also rely on these pairwise judgments.
This signal complements the proxy: the proxy captures how well a model learns under a given budget pairwise comparisons capture the underlying quality of the solution After each comparison, Bradley-Terry strength estimates are recomputed globally over the full history of battles. This produces stable, path-independent rankings that remain consistent as more evidence accumulates.
What the data shows:
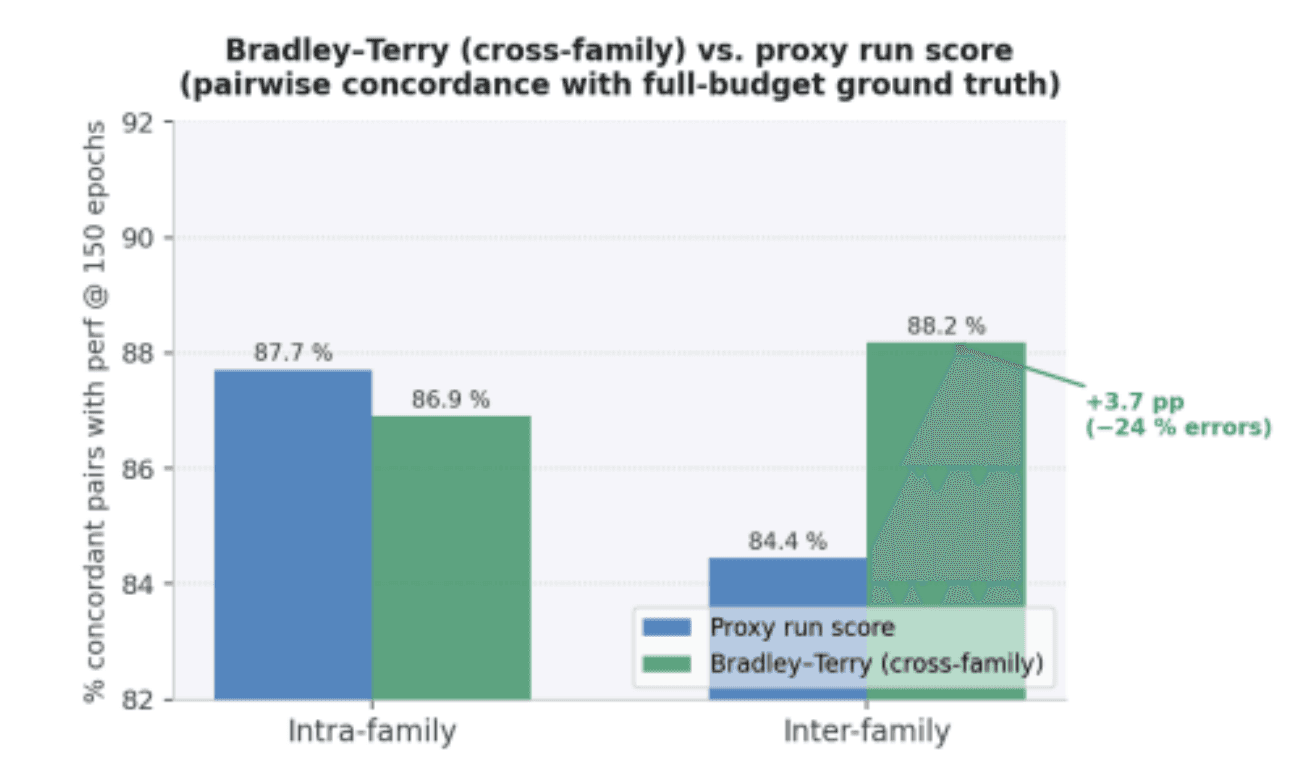
Figure 5: Pairwise ranking agreement with full-training ground-truth performance, split by intra- and inter-family pairs. Cross-family BT (green) beats proxy scores (blue) by 3.7% on inter-family pairs - 24% fewer ranking errors. Within families, the proxy is marginally better (87.7% vs. 86.9%).
The empirical result is clean. Across 45 nodes from 6 families, BT improves inter family ranking agreement by 3.7% - equivalent to 24% fewer ranking errors when comparing candidates across different architectural families. Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 10 Within a family, the proxy is actually slightly better (87.7% vs. 86.9%). This makes sense: an LLM judge looking at two nearly identical scripts from the same family cannot reliably detect subtle differences in numerical stability or regularization choices. The proxy trajectory captures exactly these effects. BT is not a replacement for proxy scoring - it is a complement that activates where the proxy is structurally weakest.
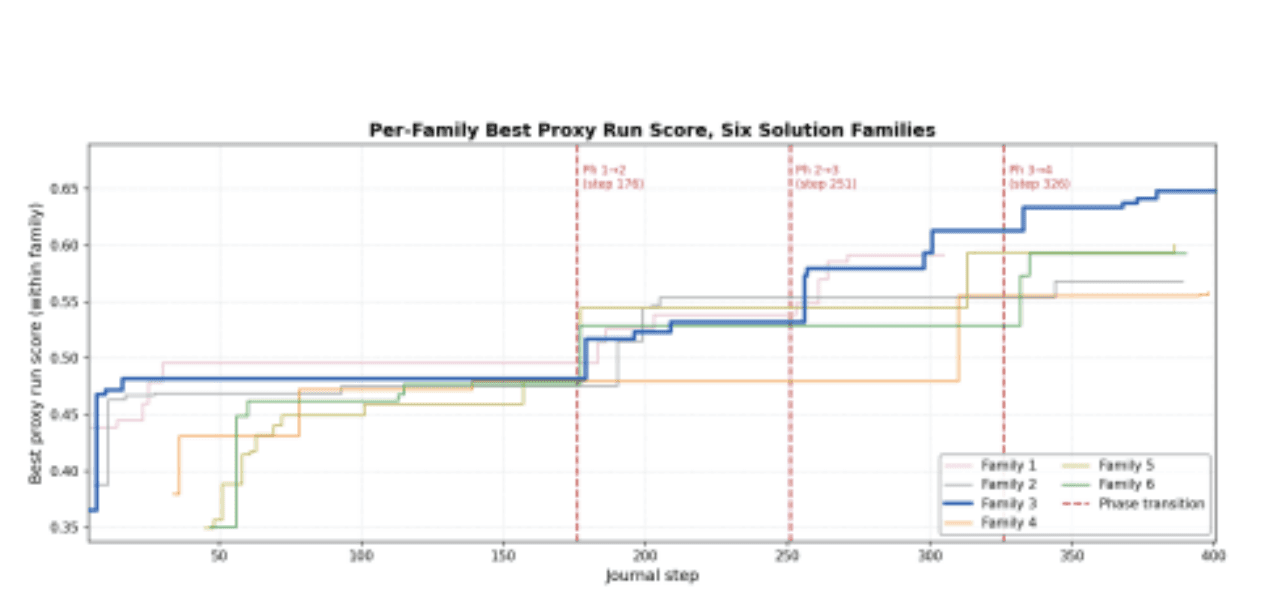
Figure 6: Best proxy score per family over journal steps. Family 3 tracks the pack early, starts separating in Phase 3, and pulls decisively ahead after the Phase 3→4 transition.
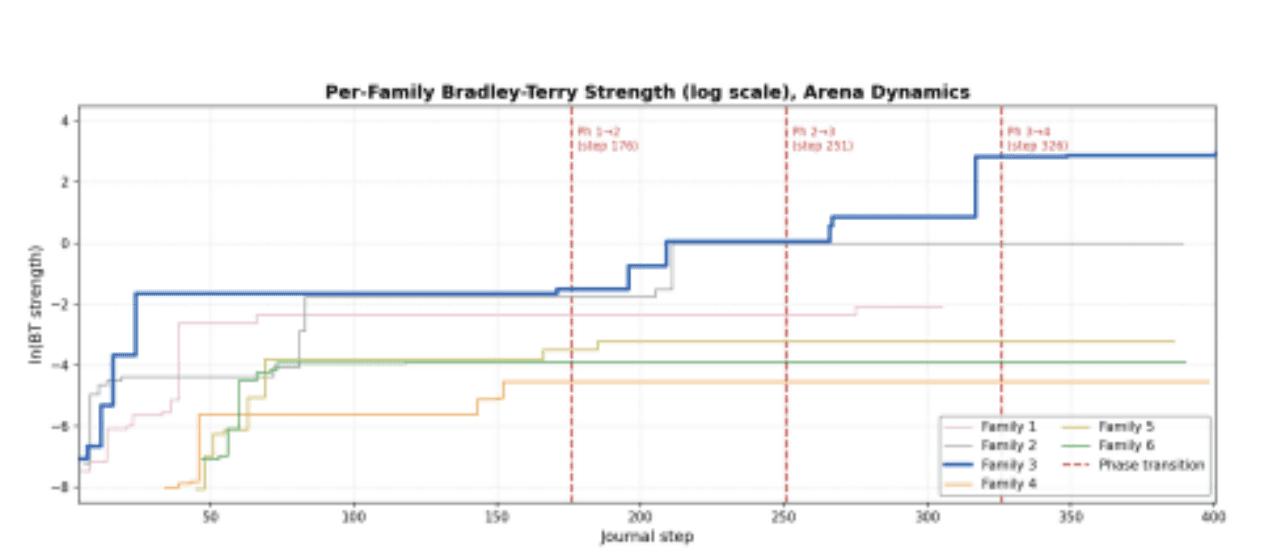
Figure 7: Bradley-Terry strength per family (log scale). Family 3 ends at BT ≈ 19.07 - more than an order of magnitude above every other family. Family 2 reaches BT ≈ 0.99 despite having the second-lowest proxy score, illustrating that the two signals capture different things.
BT as the cross-phase bridge
The phase incomparability problem is where Bradley-Terry becomes essential. Each time the Overseer increases proxy fidelity, the measurement scale changes.
A score obtained in Phase 1 cannot be meaningfully compared to a score obtained in Phase 3. Without an additional signal, you lose the ability to rank candidates across phases. Bradley-Terry does not have this limitation.
Because it relies on direct comparisons between solutions, it remains independent of the proxy configuration. A candidate discovered early in the run can still be meaningfully compared to one discovered much later.
This makes BT the only signal that remains consistent across phase transitions. When proxy scores reset, BT rankings carry forward.
In practice, we combine both signals into a single score:
s = α · p̃+ β · w_b(n_b) · b̃
Within a phase, both the proxy score p̃and the normalised log-BT strength b̃contribute with equal weights (α = β = 0.5).
Across phases, only b̃is used for ranking candidates from different phases, since p̃values are not comparable. The weight w_b ramps up gradually as battles accumulate, preventing BT from having outsized influence before enough evidence exists.
Error handling: why the Overseer makes runs reliable
Beyond stagnation detection, the Overseer handles a class of problem that would otherwise silently eat evaluation budget: recurring structural failures. During the Ventilator run, we observed multiple nodes failing with identical truncation signatures - coding agents were generating Python scripts that Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 12 exceeded LLM output token limits, producing code that ended mid-function and could not run at all.
The Overseer detected the pattern at steps 51–75 and injected a process note into the system prompts of all coding agents: “Multiple draft nodes are failing due to code truncation. Keep initial draft implementations concise with a minimal feature set to avoid output token limits. Add complex feature engineering later during the improve phase.”
No architecture suggestion, no hyperparameter. Just a structural constraint. The note worked. The same issue re-emerged late in the run (steps 263, 281) when feature engineering blocks grew large again in complexity.
The Overseer updated its note: “WARNING: Excessively long feature engineering blocks are causing code truncation and node failures. Keep feature engineering strictly concise and modular.” Without this loop, these failures would have required a human to notice, diagnose, restart. With it, the run corrects itself. The overall buggy node rate across 392 candidates was 2.5%.
One run, and it works
The practical payoff of all of this is simple: you launch once and get a good result. Before the Overseer, running MLEvolve on a new task was a calibration process spread across multiple launches.
First launch: proxy settings are wrong, stagnation in the first hour. Second launch: proxy is better but the timeout is too tight, candidates are killed mid-training.
Third launch: something else. Each iteration costs hours and requires someone with enough ML context to interpret what went wrong. With the Overseer, the initialization step replaces the first one or two pilot runs.
The rapid self-correction property - the Overseer observes actual runtimes after a few completed evaluations and recalibrates before significant budget is wasted - replaces the subsequent ones. You do not need to know in advance what the right proxy size is for this task.
The system converges to it. Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 13 The Ventilator result: a single ~14-hour run, no task-specific configuration, no pilot tuning, no human intervention after launch. Final MAE: 0.1354, state-of-the-art, beating every previously published method - including frameworks given a 24 hour budget.
The ablation tells the story quantitatively:


With a fixed proxy, scores saturate early and the search overfits to a frozen, uninformative signal. Progress in proxy score does not transfer to test performance. The adaptive proxy keeps the evaluation discriminative throughout the run, and the BT arena ensures that cross-family and cross-phase comparisons remain valid even as the proxy changes.
What’s next: letting the Overseer control search allocation too
Right now, the Overseer controls how much compute each candidate receives (evaluation fidelity), but not how the search itself is explored (the balance between trying new ideas vs. refining the best ones).
In practice, this balance is governed by a parameter that determines how much the system favors exploration over exploitation. Today, this is fixed for the entire run.
A natural next step is to let the Overseer adjust it dynamically. Early in the search, you want broad exploration with cheap evaluations to maximize diversity.
Later, you want to focus compute on the most promising directions with more expensive evaluations. Letting the Overseer coordinate both would make the search much more efficient within the same time budget.
More broadly, the Overseer could also take control of how candidates are scored and ranked. Today, we rely on a fixed combination of signals: a proxy evaluation that looks at how a model learns under constraints, and pairwise comparisons between solutions.
These signals are aggregated in a predefined way to decide which candidates are better. Self-Improving ML Search: Reliable Evaluation That Beats Existing Agents 14
In the future, this aggregation itself could become adaptive. Depending on the stage of the search, the Overseer could shift emphasis between different signals, for example relying more on fast proxy feedback early on, and more on deeper comparisons once candidates become harder to distinguish.
The goal is not to change what we measure, but how we weigh and interpret it over time. This would extend the Overseer’s role from simply allocating compute to fully orchestrating the search: deciding not only how much to evaluate and where to explore, but also how to interpret results when ranking candidates.
In short
The Overseer Agent exists because, in autonomous ML search, how you evaluate candidates matters just as much as what you generate. A proxy that has saturated doesn’t just stop helping, it starts actively misleading the search. A ranking signal that survives phase transitions isn’t a nice-to-have, it’s the only way to keep comparisons meaningful as the system evolves. And the ability to detect structural failures and correct them mid-run isn’t clever engineering, it’s what turns a fragile experiment into a system you can actually rely on.
In the end, the breakthrough isn’t better models, it’s better judgment.


